Posted by Natalie Silvanovich, Project Zero
On January 29, 2019, a serious vulnerability was discovered in Group FaceTime which allowed an attacker to call a target and force the call to connect without user interaction from the target, allowing the attacker to listen to the target’s surroundings without their knowledge or consent. The bug was remarkable in both its impact and mechanism. The ability to force a target device to transmit audio to an attacker device without gaining code execution was an unusual and possibly unprecedented impact of a vulnerability. Moreover, the vulnerability was a logic bug in the FaceTime calling state machine that could be exercised using only the user interface of the device. While this bug was soon fixed, the fact that such a serious and easy to reach vulnerability had occurred due to a logic bug in a calling state machine -- an attack scenario I had never seen considered on any platform -- made me wonder whether other state machines had similar vulnerabilities as well. This post describes my investigation into calling state machines of a number of messaging platforms, including Signal, JioChat, Mocha, Google Duo, and Facebook Messenger.
WebRTC and State Machines
The majority of video conferencing applications are implemented using WebRTC, which I’ve discussed in several past blog posts. WebRTC connections are created by exchanging call set-up information in Session Description Protocol (SDP) between peers, a process which is called signalling. Signalling is not implemented by WebRTC, which allows peers to exchange SDP in whatever secure communication message is available to them, usually WebSockets for web applications, and secure messaging for messaging applications.
There are a few types of SDP that can be exchanged by WebRTC peers. In a typical connection, the caller starts off by sending an SDP offer, and then the callee responds with an SDP answer. These messages contain most information that is needed to transmit and receive media, including codec support, encryption keys and much more. After the offer/answer exchange, peers can send SDP candidates to other peers. Candidates are potential network paths that the two peers can use to connect to each other, and SDP candidates contain information such as IP addresses and TURN servers. Peers usually send more than one candidate to a peer, and candidates can be sent at any time during a connection.
WebRTC connections maintain an internal state related to whether an offer or answer has been received and processed, however, applications that use WebRTC usually have to maintain their own state machine to manage the user state of the application. How the user state maps to the WebRTC state is a design choice made by the WebRTC integrator, which has both security and performance consequences. For example, some applications do not exchange any SDP until the callee user has interacted with the application to answer the call, meanwhile others set up the peer-to-peer connection, and start sending audio and video from caller to callee before the callee is even notified of the call.
Regardless of design, transmitting audio or video from an input device must be directly enabled by application code using WebRTC. This is usually done using a feature called tracks. Every input device is considered a ‘track’, and each specific track must be added to a specific peer connection by calling addTrack (or language equivalent) before audio or video is transmitted. Tracks can also be disabled, which is useful for implementing mute and camera-off features. Each track also has an RTPSender property that can be used to fine-tune the properties of transmission, which can also be used to disable audio or video transmission.
Theoretically, ensuring callee consent before audio or video transmission should be a fairly simple matter of waiting until the user accepts the call before adding any tracks to the peer connection. However, when I looked at real applications they enabled transmission in many different ways. Most of these led to vulnerabilities that allowed calls to be connected without interaction from the callee.
Signal Messenger
I looked at Signal in September 2019, and at that time, the application had a calling setup that is very similar to what is recommended in WebRTC documentation.

A peer-to-peer connection is established, and then the callee's audio track is added to the connection when the callee accepts the call by interacting with the user interface. Then a message is sent to the caller via the peer-to-peer connection, telling it to also move to the connected state and add the track.
Unfortunately, the application didn’t check that the device receiving the connect message was the caller device, so it was possible to send a connect message from the caller device to the callee. This caused the audio call to connect, allowing the caller to hear the callee’s surroundings. I tested this bug by changing Signal’s open-source code to send the message and recompiling the attacking client.
This vulnerability was fixed in the client in September 2019, and since then, Signal’s signalling code has been replaced by the ringrtc project, which uses a more conservative state machine.
This bug was purely in Signal’s code, and was not due to a misunderstanding of WebRTC functionality. The state machine design was largely effective requiring user consent to transmit audio, but a specific check was not implemented.
JioChat and Mocha
I accidentally found two very similar vulnerabilities in JioChat and Mocha messengers in July 2020 while testing whether a WebRTC exploit would work on them. They both had a similar signalling design, which was server-mediated.

The offer and answer are exchanged via the server, and then both the caller and the callee send their candidates to the server. The server then stores them until the callee interacts with their device and accepts the call. Then the peer-to-peer connection is created, and when WebRTC enters into its internal connected state, the track is added, causing audio and video to be transmitted.
This design has a fundamental problem, as candidates can be optionally included in an SDP offer or answer. In that case, the peer-to-peer connection will start immediately, as the only thing preventing the connection in this design is the lack of candidates, which will in turn lead to transmission from input devices. I tested this by using Frida to add candidates to the offers created by each of these applications. I was able to cause JioChat to send audio without user consent, and Mocha to send audio and video. Both of these vulnerabilities were fixed soon after they were filed by filtering SDP on the server.
These issues were caused by a misunderstanding of how WebRTC works coupled with an attempt to improve WebRTC performance with an unusual signalling design. Normally, WebRTC integrators have to decide whether to wait until the callee has answered the call to set up the peer-to-peer connection. Setting the connection up early improves performance and prevents the user from having to wait when they answer a call, but also greatly increases the remote attack surface of WebRTC. These applications tried to improve performance without the security cost with this design, but didn’t consider all the ways that WebRTC can start a peer-to-peer connection.
It is generally not a good idea for integrators to gate audio or video transmission on any WebRTC feature that is not adding or enabling tracks. To start, many WebRTC features are complex, so it is easy to make a mistake that allows audio or video to be transmitted. Also, if the feature that is gated on is not commonly-used or not a security feature, it could be poorly tested or changed in the future.
Duo
I looked at Google Duo in September 2020. Duo’s signalling methodology is somewhat different from a lot of messengers because it supports a feature that allows the callee to preview the caller’s video before answering. So a one-way video stream needs to be set up before the call is answered.

The image above shows the setup of the one-way video stream. Dotted lines represent asynchronous calls made using Java executors. The lack of transmission from callee to caller is enforced by two methods. First, the SDP offer contains the property a=sendonly for video, which causes video to only be transmitted in one direction. Also, when the callee receives the offer from the caller, it adds the video track to the peer connection, but then disables it using the RTPSender property of the track (the audio track is not added or enabled until the user accepts the call).
Neither of these methods effectively prevents video from being transmitted from callee to caller. The SDP property is easy to get around because the caller provides the SDP to the callee, so it can be easily altered. Disabling the video track as soon as the offer is processed should work, except for the asynchronous design. Normally, the setLocalDescription method (which processes the SDP offer) calls the callback onSetSuccess, and then sets up the peer-to-peer connection after the callback has finished. However, if the callback makes another asynchronous call, the guarantee that onSetSuccess finishes before the connection is set up no longer holds, because the setLocalDescription method only waits for the onSetSuccess thread to finish. This creates a race between disabling the video and setting up the connection, so in some situations, the callee could transmit a few video frames to the caller before transmission is disabled.
I tested this by using Frida to alter the SDP sent by the callee, and then I tried many methods to win the race. It turned out to be fairly hard to win, and I spent roughly two weeks trying to figure out how to slow down the video disable call enough to give the connection time to set up. I ended up sending multiple offers and adding candidates to the offers, which decreased the connection time, as the network connection was already established. Then I sent many messages that take a long time to process through the data channel of the peer-to-peer connection to slow down the disabling of the video track. Data messages are processed on the same thread queue as disabling the video track in Duo, so sending data messages filled up the queue that was needed to disable video with many other entries, delaying the track being disabled.
This bug was fixed in December 2020 by removing the asynchronous call from onSetSuccess. While Duo generally designed signalling in a way that is effective in preventing video transmission from callee to caller, implementing the design asynchronously introduced problems. Asynchronous signalling implementations are becoming more common on mobile applications, as there are many unpredictable situations in which WebRTC needs to wait on the network or a peer, and separating function calls into different threads means a delay in one call won’t affect unrelated functionality. However, asynchronous calls make it more difficult to model how a state machine will behave in all situations, so it is important to be cautious about adding asynchronous calls to WebRTC signalling. In this case, the asynchronous call to disable the video track added nothing in terms of performance, as there is no reason any of the calls made to disable the track could block, and onSetSuccess already runs in its own thread and can yield to higher priority threads. It’s important to balance the risk and benefit of asynchronous calls and not indiscriminately include them in an application.
Facebook Messenger
I looked at Facebook Messenger in October 2020. It was a fairly challenging target because of the amount of reverse engineering required. Stepping back a bit, WebRTC has bindings in several programming languages which allow it to be integrated into applications using that language. Most Android applications that integrate WebRTC use the Java bindings. This makes investigating signalling state machines fairly straightforward, as important Java functions, such as setLocalDescription (which processes offers and answers), addRemoteIceCandidate (which processes candidates) and addTrack (which adds tracks to connections) can be hooked in Frida and logged for analysis. It is also reasonably straightforward to change the behavior of the attacker device using these calls.
Facebook Messenger does not use Java bindings to integrate WebRTC, instead it uses C++ bindings. Moreover, it statically links WebRTC to a larger library (librtcR20.so, which is likely the rsys library mentioned in this article), so the symbols for calls to bindings get stripped, making them difficult to hook. In addition, Facebook Messenger serializes SDP into another format before it is transmitted, so it is difficult to determine how signalling works by monitoring traffic.
I eventually realized that the only reasonable way to figure out how Facebook Messenger signalling works was to figure out its network protocol. Thankfully, Facebook has publicly stated that they use fbthrift, a branch of thrift. I loaded the librtcR20.so library into IDA to see if I could find where it called into the thrift library, but while there were a few calls, it looked like the code was mostly statically linked. I eventually figured out that this is because thrift generates serialization code for every protocol implemented, so most of the serialization and deserialization code ends up compiled with the protocol processing code. So I decided to compile fbthrift, make a sample serializer and look at it in IDA, so I could get an impression of what compiled fbthrift serializers look like. I noticed that during serialization, members of an object are serialized by calling a method called writeFieldBegin. I also noticed that when this method is called, the field name is required, even though it is usually not included in the serialized output. So I looked for a function in librtcR20 that was very frequently called with different string parameters that seemed reasonable for field names. Not very many functions fulfilled that criteria, so I was able to identify writeFieldBegin.

At this point, I could find many places where objects are serialized, and needed to identify which one was the message used to set up WebRTC calls.
Earlier, I’d noticed a method in the library called P2PCall::OnP2PMessageFromPeer (note that the symbol for this method is stripped, but the method name is logged when it is called). This seemed a likely place that a deserialized message would be processed. Searching for the string “P2PMessage”, I found the serialization code for a type called P2PMessageRequest. I assumed that this was where call setup messages were created.
Thrift serialization code is generated based on class definitions in a thrift definition file. Based on the field names and types passed to writeFieldBegin, I was able to slowly reverse engineer the complete thrift definition for this type. It was tedious work, because the definition was fairly long, and the code is obfuscated in a way that makes register use inconsistent, so I wasn’t confident that any automated approach would be accurate.
Below is a sample of the serialization code.
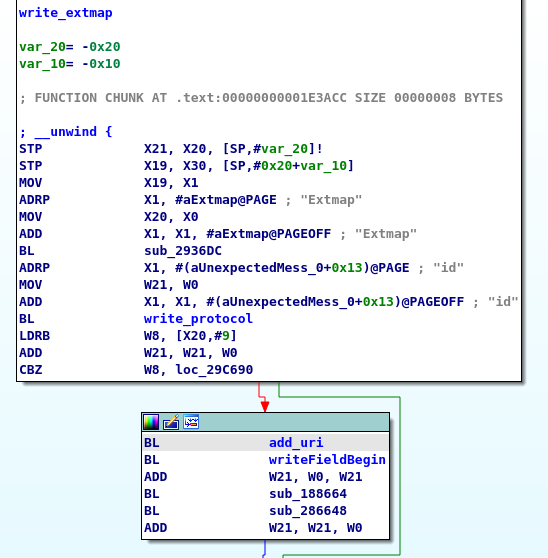
Notice that it writes two fields from an object of type Extmap. The first, named id, is a mandatory field. The function that writes the code is as follows.

The field identifier written is 1, and the field type is 8, which translates to i32 (32-bit integer). The second field is an optional field, and the registers to write it are set in the following code.

This sets the field name to uri, the field identifier to 2, and the field type to 8 (also i32). All together, this code can be represented by the following thrift definition.
```
struct Extmap{
1: i32 id
2: optional i32 uri
}
```
After similarly reverse engineering every field of the P2PMessageRequest type, I had a complete thrift definition, available here.
I did two things with this thrift definition. First, I used it to determine the layout of the P2PMessageRequest type in C++. This was extremely valuable, as it allowed me to load the struct definition into IDA with every single field named correctly. This made it much easier to understand how incoming messages are handled in P2PCall::OnP2PMessageFromPeer. This ended up being a bit of a process. fbthrift can generate C++ header files directly from a thrift definition, but these are very long and contain a lot of unnecessary definitions, and can not be processed by IDA. So I ended up compiling the generated source and loading it into IDA, and then exporting the structure definitions and importing them into another IDA instance where librtcR20.so was already loaded. A few fields had different sizes in my compilation versus Facebook’s, but it was close enough that I could get it to work with a few modifications.
Below is an example of code decompiled in IDA with the thrift definition imported, to give an idea of how much easier it makes it to understand the processing of the message object.

I was also able to decode and generate messages sent over the network. To do this, I generated the serialization code from the thrift definition in Python, as thrift supports code generation in many languages. Then, I was able to import this code when using Frida Python to hook functions in Facebook Messenger.
Then I needed to find the code that handled incoming P2PMessageRequest messages. Since these messages are handled by native code, meanwhile most Facebook messages are handled by Java code, I looked for a native call with an appropriate name. I found com.facebook.webrtc.WebrtcEngine.onThriftMessageFromPeer. I hooked this method with Frida, and fed its byte array parameter in the generated deserializer, and it decoded incoming messages.
I found a similar method used to send thrift messages, sendThriftToPeer (this method’s class name is obfuscated and changes in every version of Facebook Messenger, but it can be found by grepping the application’s smali). I was also able to hook this method, and alter its byte array parameter, to change a P2PMessageRequest message sent by Facebook Messenger.
Now, I was able to understand Facebook Messenger’s signalling state machine. There are two different ways that signalling can occur, depending on where the user is signed into Facebook Messenger. If the user is signed in on multiple devices or browsers, very little happens before the callee interacts with their device. The offer, answer and candidates are exchanged, but they are stored by the callee device and not processed until the callee user answers the call. This makes sense, because Facebook Messenger doesn’t know what device to connect to otherwise.
If the callee is only signed in on a single device, the state machine is more interesting.

In this case, Facebook Messenger enables the track as soon as an offer is received, but alters the offer so that all outgoing streams are inactive. It then replaces the offer with one where they are active when the user interacts with the device.
I was concerned that there might be a way to bypass the alteration of the offer, but I looked at how this was done, and while I generally don’t recommend using anything other than adding or disabling tracks to disable input device transmission, it was fairly robust. The offer is altered after the SDP is decoded into an internal WebRTC object, and the changes are made directly to this object, which eliminates the possibility of parsing errors.
However, looking at how incoming messages are handled, I noticed that many message types other than offers, answers and candidates are processed before the call is answered. One type that stood out was called SdpUpdate. When an SdpUpdate message is received, the local offer or answer is updated by calling setLocalDescription.
This message type didn’t do anything when sent to the state machine above, as it is already storing SDP and waiting to call setLocalDescription. But in the situation where the user is logged into two devices, it caused setLocalDescription to be called and started the audio connection.
It is not clear what the SdpUpdate message type is used for in Facebook Messenger. I tried many scenarios on my test devices, including network switchover, and was not able to generate one in normal use. Regardless, it is clear that it was not intended for this message type to be received before the call is answered. It is similar to the Signal bug described above, in that it is not related to the application’s use of WebRTC, but due to a missing check when handling input that can cause state transitions.
This vulnerability was fixed in November 2020 with server changes that prevent this message type from being sent before a call is connected.
Other Applications
There were a few other applications I looked at and did not find problems with their state machines. I looked at Telegram in August 2020, right after video conferencing was added to the application. I did not find any problems, largely because the application does not exchange the offer, answer or candidates until the callee has answered the call. I looked at Viber in November 2020, and did not find any problems with their state machine, though challenges reverse engineering the application made this analysis less rigorous than the other applications I looked at.
Discussion
The majority of calling state machines I investigated had logic vulnerabilities that allowed audio or video content to be transmitted from the callee to the caller without the callee’s consent. This is clearly an area that is often overlooked when securing WebRTC applications.
The majority of the bugs did not appear to be due to developer misunderstanding of WebRTC features. Instead, they were due to errors in how the state machines are implemented. That said, a lack of awareness of these types of issues was likely a factor. It is rare to find WebRTC documentation or tutorials that explicitly discuss the need for user consent when streaming audio or video from a user’s device.
Many of these state machines had needless complexity in how they handled call set-up, which was also a factor. Unnecessary threading, reliance on obscure features and large numbers of states and input types increase the likelihood of this type of vulnerability occurring in a signalling state machine.
It is also concerning to note that I did not look at any group calling features of these applications, and all the vulnerabilities reported were found in peer-to-peer calls. This is an area for future work that could reveal additional problems.
Conclusion
I investigated the signalling state machines of seven video conferencing applications and found five vulnerabilities that could allow a caller device to force a callee device to transmit audio or video data. All these vulnerabilities have since been fixed. It is not clear why this is such a common problem, but a lack of awareness of these types of bugs as well as unnecessary complexity in signalling state machines is likely a factor. Signalling state machines are a concerning and under-investigated attack surface of video conferencing applications, and it is likely that more problems will be found with further research.
No comments:
Post a Comment