Posted by Ivan Fratric, Project Zero
tl;dr I combined Fuzzilli (an open-source JavaScript engine fuzzer), with TinyInst (an open-source dynamic instrumentation library for fuzzing). I also added grammar-based mutation support to Jackalope (my black-box binary fuzzer). So far, these two approaches resulted in finding three security issues in jscript9.dll (default JavaScript engine used by Internet Explorer).
Introduction or “when you can’t beat them, join them”
In the past, I’ve invested a lot of time in generation-based fuzzing, which was a successful way to find vulnerabilities in various targets, especially those that take some form of language as input. For example, Domato, my grammar-based generational fuzzer, found over 40 vulnerabilities in WebKit and numerous bugs in Jscript.
While generation-based fuzzing is still a good way to fuzz many complex targets, it was demonstrated that, for finding vulnerabilities in modern JavaScript engines, especially engines with JIT compilers, better results can be achieved with mutational, coverage-guided approaches. My colleague Samuel Groß gives a compelling case on why that is in his OffensiveCon talk. Samuel is also the author of Fuzzilli, an open-source JavaScript engine fuzzer based on mutating a custom intermediate language. Fuzzilli has found a large number of bugs in various JavaScript engines.
While there has been a lot of development on coverage-guided fuzzers over the last few years, most of the public tooling focuses on open-source targets or software running on the Linux operating system. Meanwhile, I focused on developing tooling for fuzzing of closed-source binaries on operating systems where such software is more prevalent (currently Windows and macOS). Some years back, I published WinAFL, the first performant AFL-based fuzzer for Windows. About a year and a half ago, however, I started working on a brand new toolset for black-box coverage-guided fuzzing. TinyInst and Jackalope are the two outcomes of this effort.
It comes somewhat naturally to combine the tooling I’ve been working on with techniques that have been so successful in finding JavaScript bugs, and try to use the resulting tooling to fuzz JavaScript engines for which the source code is not available. Of such engines, I know two: jscript and jscript9 (implemented in jscript.dll and jscript9.dll) on Windows, which are both used by the Internet Explorer web browser. Of these two, jscript9 is probably more interesting in the context of mutational coverage-guided fuzzing since it includes a JIT compiler and more advanced engine features.
While you might think that Internet Explorer is a thing of the past and it doesn’t make sense to spend energy looking for bugs in it, the fact remains that Internet Explorer is still heavily exploited by real-world attackers. In 2020 there were two Internet Explorer 0days exploited in the wild and three in 2021 so far. One of these vulnerabilities was in the JIT compiler of jscript9. I’ve personally vowed several times that I’m done looking into Internet Explorer, but each time, more 0days in the wild pop up and I change my mind.
Additionally, the techniques described here could be applied to any closed-source or even open-source software, not just Internet Explorer. In particular, grammar-based mutational fuzzing described two sections down can be applied to targets other than JavaScript engines by simply changing the input grammar.
Approach 1: Fuzzilli + TinyInst
Fuzzilli, as said above, is a state-of-the-art JavaScript engine fuzzer and TinyInst is a dynamic instrumentation library. Although TinyInst is general-purpose and could be used in other applications, it comes with various features useful for fuzzing, such as out-of-the-box support for persistent fuzzing, various types of coverage instrumentations etc. TinyInst is meant to be simple to integrate with other software, in particular fuzzers, and has already been integrated with some.
So, integrating with Fuzzilli was meant to be simple. However, there were still various challenges to overcome for different reasons:
Challenge 1: Getting Fuzzilli to build on Windows where our targets are.
Edit 2021-09-20: The version of Swift for Windows used in this project was from January 2021, when I first started working on it. Since version 5.4, Swift Package Manager is supported on Windows, so building Swift code should be much easier now. Additionally, static linking is supported for C/C++ code.
Fuzzilli was written in Swift and the support for Swift on Windows is currently not great. While Swift on Windows builds exist (I’m linking to the builds by Saleem Abdulrasool instead of the official ones because the latter didn’t work for me), not all features that you would find on Linux and macOS are there. For example, one does not simply run swift build on Windows, as the build system is one of the features that didn’t get ported (yet). Fortunately, CMake and Ninja support Swift, so the solution to this problem is to switch to the CMake build system. There are helpful examples on how to do this, once again from Saleem Abdulrasool.
Another feature that didn’t make it to Swift for Windows is statically linking libraries. This means that all libraries (such as those written in C and C++ that the user wants to include in their Swift project) need to be dynamically linked. This goes for libraries already included in the Fuzzilli project, but also for TinyInst. Since TinyInst also uses the CMake build system, my first attempt at integrating TinyInst was to include it via the Fuzzilli CMake project, and simply have it built as a shared library. However, the same tooling that was successful in building Fuzzilli would fail to build TinyInst (probably due to various platform libraries TinyInst uses). That’s why, in the end, TinyInst was being built separately into a .dll and this .dll loaded “manually” into Fuzzilli via the LoadLibrary API. This turned out not to be so bad - Swift build tooling for Windows was quite slow, and so it was much faster to only build TinyInst when needed, rather than build the entire Fuzzilli project (even when the changes made were minor).
The Linux/macOS parts of Fuzzilli, of course, also needed to be rewritten. Fortunately, it turned out that the parts that needed to be rewritten were the parts written in C, and the parts written in Swift worked as-is (other than a couple of exceptions, mostly related to networking). As someone with no previous experience with Swift, this was quite a relief. The main parts that needed to be rewritten were the networking library (libsocket), the library used to run and monitor the child process (libreprl) and the library for collecting coverage (libcoverage). The latter two were changed to use TinyInst. Since these are separate libraries in Fuzzilli, but TinyInst handles both of these tasks, some plumbing through Swift code was needed to make sure both of these libraries talk to the same TinyInst instance for a given target.
Challenge 2: Threading woes
Another feature that made the integration less straightforward than hoped for was the use of threading in Swift. TinyInst is built on a custom debugger and, on Windows, it uses the Windows debugging API. One specific feature of the Windows debugging API, for example WaitForDebugEvent, is that it does not take a debugee pid or a process handle as an argument. So then, the question is, if you have multiple debugees, to which of them does the API call refer? The answer to that is, when a debugger on Windows attaches to a debugee (or starts a debugee process), the thread that started/attached it is the debugger. Any subsequent calls for that particular debugee need to be issued on that same thread.
In contrast, the preferred Swift coding style (that Fuzzilli also uses) is to take advantage of threading primitives such as DispatchQueue. When tasks get posted on a DispatchQueue, they can run in parallel on “background” threads. However, with the background threads, there is no guarantee that a certain task is always going to run on the same thread. So it would happen that calls to the same TinyInst instance happened from different threads, thus breaking the Windows debugging model. This is why, for the purposes of this project, TinyInst was modified to create its own thread (one for each target process) and ensure that any debugger calls for a particular child process always happen on that thread.
Various minor changes
Some examples of features Fuzzilli requires that needed to be added to TinyInst are stdin/stdout redirection and a channel for reading out the “status” of JavaScript execution (specifically, to be able to tell if JavaScript code was throwing an exception or executing successfully). Some of these features were already integrated into the “mainline” TinyInst or will be integrated in the future.
After all of that was completed though, the Fuzzilli/Tinyinst hybrid was running in a stable manner:
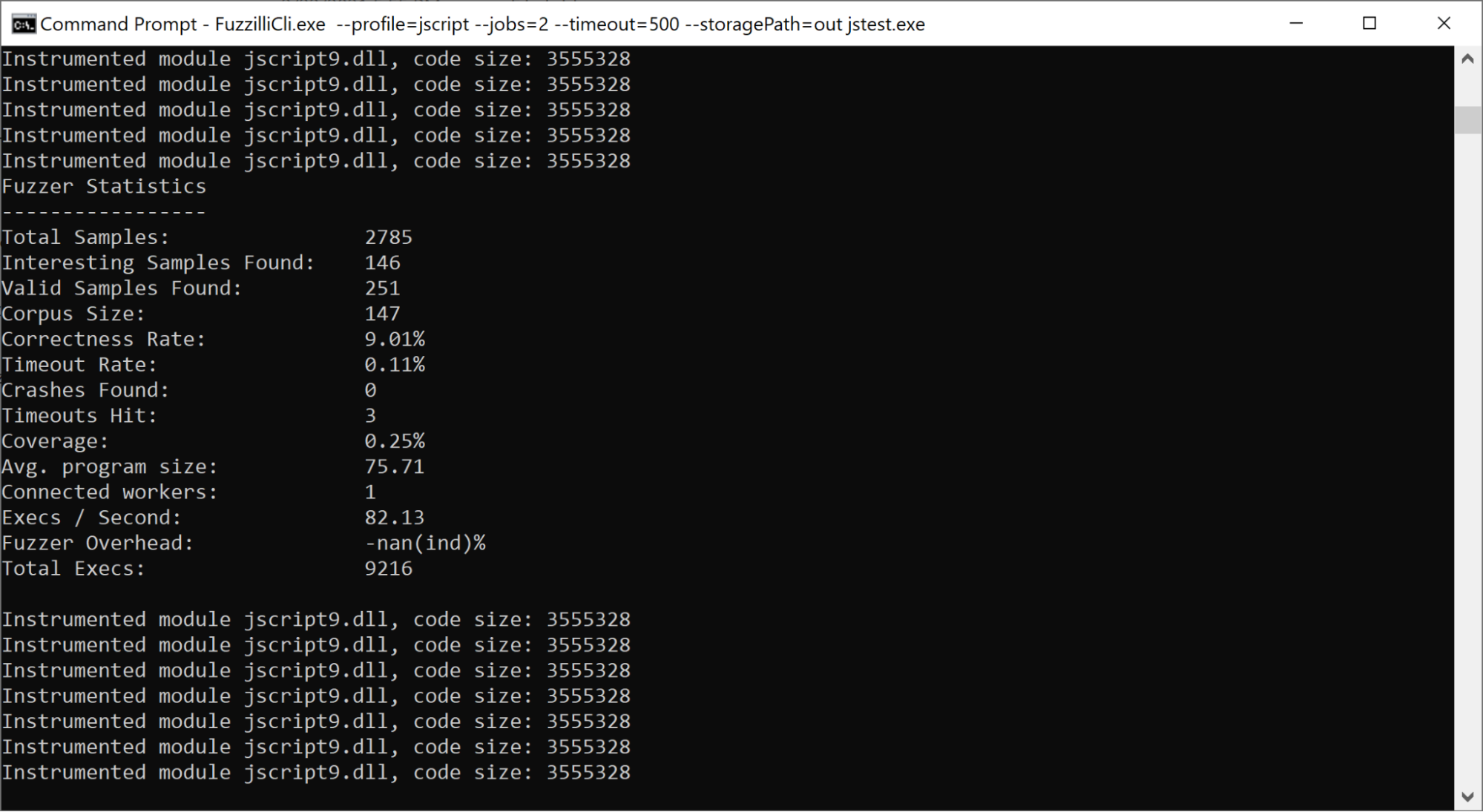
Note that coverage percentage reported by Fuzzilli is incorrect. Because TinyInst is a dynamic instrumentation library, it cannot know the number of basic blocks/edges in advance.
Primarily because of the current Swift on Windows issues, this closed-source mode of Fuzzilli is not something we want to officially support. However, the sources and the build we used can be downloaded here.
Approach 2: Grammar-based mutation fuzzing with Jackalope
Jackalope is a coverage-guided fuzzer I developed for fuzzing black-box binaries on Windows and, recently, macOS. Jackalope initially included mutators suitable for fuzzing of binary formats. However, a key feature of Jackalope is modularity: it is meant to be easy to plug in or replace individual components, including, but not limited to, sample mutators.
After observing how Fuzzilli works more closely during Approach 1, as well as observing samples it generated and the bugs it found, the idea was to extend Jackalope to allow mutational JavaScript fuzzing, but also in the future, mutational fuzzing of other targets whose samples can be described by a context-free grammar.
Jackalope uses a grammar syntax similar to that of Domato, but somewhat simplified (with some features not supported at this time). This grammar format is easy to write and easy to modify (but also easy to parse). The grammar syntax, as well as the list of builtin symbols, can be found on this page and the JavaScript grammar used in this project can be found here.
One addition to the Domato grammar syntax that allows for more natural mutations, but also sample minimization, are the <repeat_*> grammar nodes. A <repeat_x> symbol tells the grammar engine that it can be represented as zero or more <x> nodes. For example, in our JavaScript grammar, we have
<statementlist> = <repeat_statement>
telling the grammar engine that <statementlist> can be constructed by concatenating zero or more <statement>s. In our JavaScript grammar, a <statement> expands to an actual JavaScript statement. This helps the mutation engine in the following way: it now knows it can mutate a sample by inserting another <statement> node anywhere in the <statementlist> node. It can also remove <statement> nodes from the <statementlist> node. Both of these operations will keep the sample valid (in the grammar sense).
It’s not mandatory to have <repeat_*> nodes in the grammar, as the mutation engine knows how to mutate other nodes as well (see the list of mutations below). However, including them where it makes sense might help make mutations in a more natural way, as is the case of the JavaScript grammar.
Internally, grammar-based mutation works by keeping a tree representation of the sample instead of representing the sample just as an array of bytes (Jackalope must in fact represent a grammar sample as a sequence of bytes at some points in time, e.g when storing it to disk, but does so by serializing the tree and deserializing when needed). Mutations work by modifying a part of the tree in a manner that ensures the resulting tree is still valid within the context of the input grammar. Minimization works by removing those nodes that are determined to be unnecessary.
Jackalope’s mutation engine can currently perform the following operations on the tree:
- Generate a new tree from scratch. This is not really a mutation and is mainly used to bootstrap the fuzzers when no input samples are provided. In fact, grammar fuzzing mode in Jackalope must either start with an empty corpus or a corpus generated by a previous session. This is because there is currently no way to parse a text file (e.g. a JavaScript source file) into its grammar tree representation (in general, there is no guaranteed unique way to parse a sample with a context-free grammar).
- Select a random node in the sample's tree representation. Generate just this node anew while keeping the rest of the tree unchanged.
- Splice: Select a random node from the current sample and a node with the same symbol from another sample. Replace the node in the current sample with a node from the other sample.
- Repeat node mutation: One or more new children get added to a <repeat_*> node, or some of the existing children get replaced.
- Repeat splice: Selects a <repeat_*> node from the current sample and a similar <repeat_*> node from another sample. Mixes children from the other node into the current node.
JavaScript grammar was initially constructed by following the ECMAScript 2022 specification. However, as always when constructing fuzzing grammars from specifications or in a (semi)automated way, this grammar was only a starting point. More manual work was needed to make the grammar output valid and generate interesting samples more frequently.
Jackalope now supports grammar fuzzing out-of-the box, and, in order to use it, you just need to add -grammar <path_to_grammar_file> to Jackalope’s command lines. In addition to running against closed-source targets on Windows and macOS, Jackalope can now run against open-source targets on Linux using Sanitizer Coverage based instrumentation. This is to allow experimentation with grammar-based mutation fuzzing on open-source software.
The following image shows Jackalope running against jscript9.
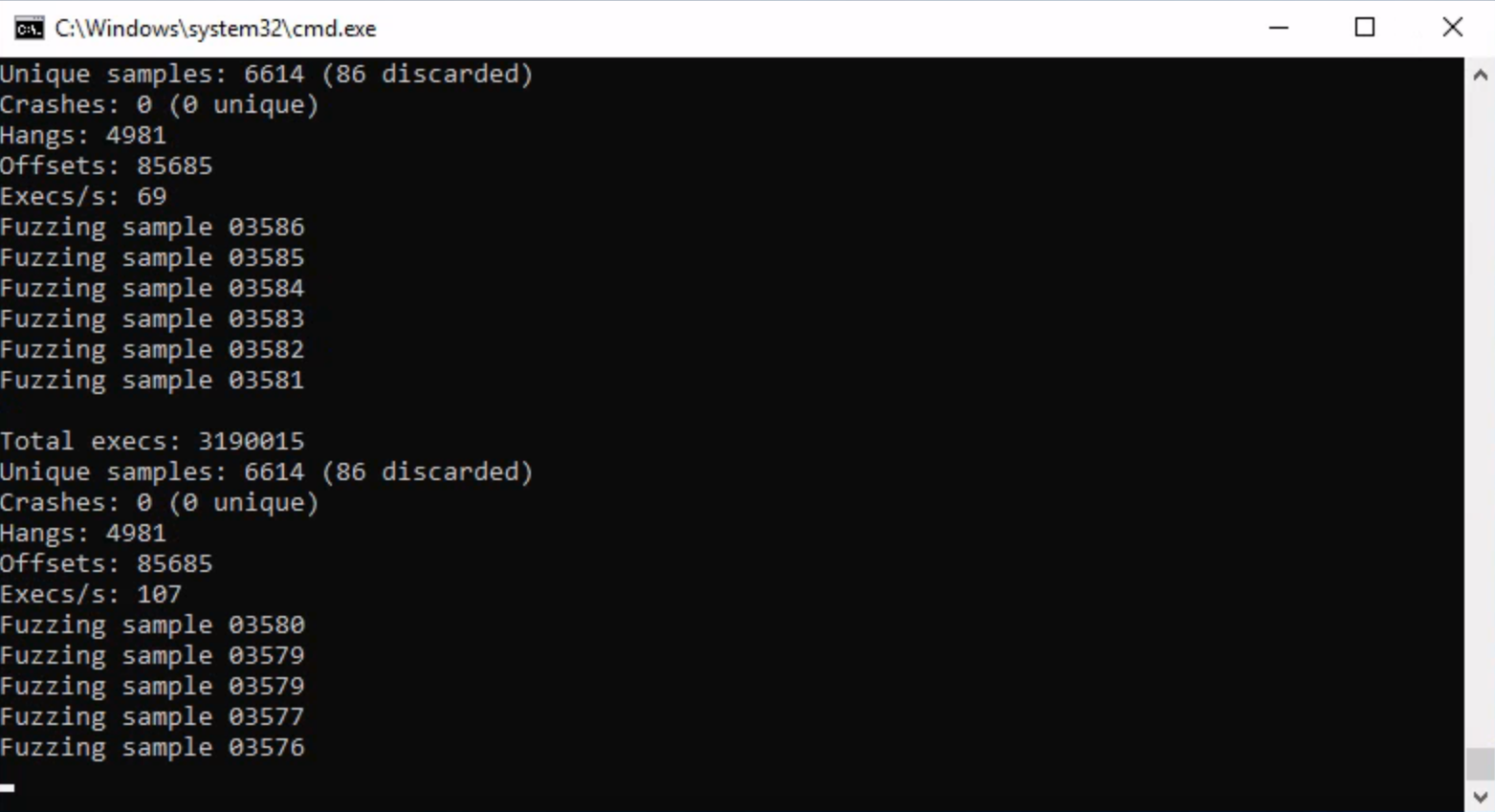
Results
I ran Fuzzilli for several weeks on 100 cores. This resulted in finding two vulnerabilities, CVE-2021-26419 and CVE-2021-31959. Note that the bugs that were analyzed and determined not to have security impact are not counted here. Both of the vulnerabilities found were in the bytecode generator, a part of the JavaScript engine that is typically not very well tested by generation-based fuzzing approaches. Both of these bugs were found relatively early in the fuzzing process and would be findable even by fuzzing on a single machine.
The second of the two bugs was particularly interesting because it initially manifested only as a NULL pointer dereference that happened occasionally, and it took quite a bit of effort (including tracing JavaScript interpreter execution in cases where it crashed and in cases where it didn’t to see where the execution flow diverges) to reach the root cause. Time travel debugging was also useful here - it would be quite difficult if not impossible to analyze the sample without it. The reader is referred to the vulnerability report for further details about the issue.
Jackalope was run on a similar setup: for several weeks on 100 cores. Interestingly, at least against jscript9, Jackalope with grammar-based mutations behaved quite similarly to Fuzzilli: it was hitting a similar level of coverage and finding similar bugs. It also found CVE-2021-26419 quickly into the fuzzing process. Of course, it’s easy to re-discover bugs once they have already been found with another tool, but neither the grammar engine nor the JavaScript grammar contain anything specifically meant for finding these bugs.
About a week and a half into fuzzing with Jackalope, it triggered a bug I hadn't seen before, CVE-2021-34480. This time, the bug was in the JIT compiler, which is another component not exercised very well with generation-based approaches. I was quite happy with this find, because it validated the feasibility of a grammar-based approach for finding JIT bugs.
Limitations and improvement ideas
While successful coverage-guided fuzzing of closed-source JavaScript engines is certainly possible as demonstrated above, it does have its limitations. The biggest one is inability to compile the target with additional debug checks. Most of the modern open-source JavaScript engines include additional checks that can be compiled in if needed, and enable catching certain types of bugs more easily, without requiring that the bug crashes the target process. If jscript9 source code included such checks, they are lost in the release build we fuzzed.
Related to this, we also can’t compile the target with something like Address Sanitizer. The usual workaround for this on Windows would be to enable Page Heap for the target. However, it does not work well here. The reason is, jscript9 uses a custom allocator for JavaScript objects. As Page Heap works by replacing the default malloc(), it simply does not apply here.
A way to get around this would be to use instrumentation (TinyInst is already a general-purpose instrumentation library so it could be used for this in addition to code coverage) to instrument the allocator and either insert additional checks or replace it completely. However, doing this was out-of-scope for this project.
Conclusion
Coverage-guided fuzzing of closed-source targets, even complex ones such as JavaScript engines is certainly possible, and there are plenty of tools and approaches available to accomplish this.
In the context of this project, Jackalope fuzzer was extended to allow grammar-based mutation fuzzing. These extensions have potential to be useful beyond just JavaScript fuzzing and can be adapted to other targets by simply using a different input grammar. It would be interesting to see which other targets the broader community could think of that would benefit from a mutation-based approach.
Finally, despite being targeted by security researchers for a long time now, Internet Explorer still has many exploitable bugs that can be found even without large resources. After the development on this project was complete, Microsoft announced that they will be removing Internet Explorer as a separate browser. This is a good first step, but with Internet Explorer (or Internet Explorer engine) integrated into various other products (most notably, Microsoft Office, as also exploited by in-the-wild attackers), I wonder how long it will truly take before attackers stop abusing it.
No comments:
Post a Comment