Posted by Jann Horn, Project Zero
On 2017-03-14, I reported a bug to Xen's security team that permits an attacker with control over the kernel of a paravirtualized x86-64 Xen guest to break out of the hypervisor and gain full control over the machine's physical memory. The Xen Project publicly released an advisory and a patch for this issue 2017-04-04.
To demonstrate the impact of the issue, I created an exploit that, when executed in one 64-bit PV guest with root privileges, will execute a shell command as root in all other 64-bit PV guests (including dom0) on the same physical machine.
Background
access_ok()
On x86-64, Xen PV guests share the virtual address space with the hypervisor. The coarse memory layout looks as follows:

Xen allows the guest kernel to perform hypercalls, which are essentially normal system calls from the guest kernel to the hypervisor using the System V AMD64 ABI. They are performed using the syscall instruction, with up to six arguments passed in registers. Like normal syscalls, Xen hypercalls often take guest pointers as arguments. Because the hypervisor shares its address space, it makes sense for guests to simply pass in guest-virtual pointers.
Like any kernel, Xen has to ensure that guest-virtual pointers don't actually point to hypervisor-owned memory before dereferencing them. It does this using userspace accessors that are similar to those in the Linux kernel; for example:
- access_ok(addr, size) for checking whether a guest-supplied virtual memory range is safe to access - in other words, it checks that accessing the memory range will not modify hypervisor memory
- __copy_to_guest(hnd, ptr, nr) for copying nr bytes from the hypervisor address ptr to the guest address hnd without checking whether hnd is safe
- copy_to_guest(hnd, ptr, nr) for copying nr bytes from the hypervisor address ptr to the guest address hnd if hnd is safe
In the Linux kernel, the macro access_ok() checks whether the whole memory range from addr to addr+size-1 is safe to access, using any memory access pattern. However, Xen's access_ok() doesn't guarantee that much:
/*
* Valid if in +ve half of 48-bit address space, or above Xen-reserved area.
* This is also valid for range checks (addr, addr+size). As long as the
* start address is outside the Xen-reserved area then we will access a
* non-canonical address (and thus fault) before ever reaching VIRT_START.
*/
#define __addr_ok(addr) \
(((unsigned long)(addr) < (1UL<<47)) || \
((unsigned long)(addr) >= HYPERVISOR_VIRT_END))
#define access_ok(addr, size) \
(__addr_ok(addr) || is_compat_arg_xlat_range(addr, size))
Xen normally only checks that addr points into the userspace area or the kernel area without checking size. If the actual guest memory access starts roughly at addr, proceeds linearly without skipping gigantic amounts of memory and bails out as soon as a guest memory access fails, only checking addr is sufficient because of the large range of non-canonical addresses, which serve as a large guard area. However, if a hypercall wants to access a guest buffer starting at a 64-bit offset, it needs to ensure that the access_ok() check is performed using the correct offset - checking the whole userspace buffer is unsafe!
Xen provides wrappers around access_ok() for accessing arrays in guest memory. If you want to check whether it's safe to access an array starting at element 0, you can use guest_handle_okay(hnd, nr). However, if you want to check whether it's safe to access an array starting at a different element, you need to use guest_handle_subrange_okay(hnd, first, last).
When I saw the definition of access_ok(), the lack of security guarantees actually provided by access_ok() seemed rather unintuitive to me, so I started searching for its callers, wondering whether anyone might be using it in an unsafe way.
Hypercall Preemption
When e.g. a scheduler tick happens, Xen needs to be able to quickly switch from the currently executing vCPU to another VM's vCPU. However, simply interrupting the execution of a hypercall won't work (e.g. because the hypercall could be holding a spinlock), so Xen (like other operating systems) needs some mechanism to delay the vCPU switch until it's safe to do so.
In Xen, hypercalls are preempted using voluntary preemption: Any long-running hypercall code is expected to regularly call hypercall_preempt_check() to check whether the scheduler wants to schedule to another vCPU. If this happens, the hypercall code exits to the guest, thereby signalling to the scheduler that it's safe to preempt the currently-running task, after adjusting the hypercall arguments (in guest registers or guest memory) so that as soon as the current vCPU is scheduled again, it will re-enter the hypercall and perform the remaining work. Hypercalls don't distinguish between normal hypercall entry and hypercall re-entry after preemption.
This hypercall re-entry mechanism is used in Xen because Xen does not have one hypervisor stack per vCPU; it only has one hypervisor stack per physical core. This means that while other operating systems (e.g. Linux) can simply leave the state of an interrupted syscall on the kernel stack, Xen can't do that as easily.
This design means that for some hypercalls, to allow them to properly resume their work, additional data is stored in guest memory that could potentially be manipulated by the guest to attack the hypervisor.
memory_exchange()
The hypercall HYPERVISOR_memory_op(XENMEM_exchange, arg) invokes the function memory_exchange(arg) in xen/common/memory.c. This function allows a guest to "trade in" a list of physical pages that are currently assigned to the guest in exchange for new physical pages with different restrictions on their physical contiguity. This is useful for guests that want to perform DMA because DMA requires physically contiguous buffers.
The hypercall takes a struct xen_memory_exchange as argument, which is defined as follows:
struct xen_memory_reservation {
/* [...] */
XEN_GUEST_HANDLE(xen_pfn_t) extent_start; /* in: physical page list */
/* Number of extents, and size/alignment of each (2^extent_order pages). */
xen_ulong_t nr_extents;
unsigned int extent_order;
/* XENMEMF flags. */
unsigned int mem_flags;
/*
* Domain whose reservation is being changed.
* Unprivileged domains can specify only DOMID_SELF.
*/
domid_t domid;
};
struct xen_memory_exchange {
/*
* [IN] Details of memory extents to be exchanged (GMFN bases).
* Note that @in.address_bits is ignored and unused.
*/
struct xen_memory_reservation in;
/*
* [IN/OUT] Details of new memory extents.
* We require that:
* 1. @in.domid == @out.domid
* 2. @in.nr_extents << @in.extent_order ==
* @out.nr_extents << @out.extent_order
* 3. @in.extent_start and @out.extent_start lists must not overlap
* 4. @out.extent_start lists GPFN bases to be populated
* 5. @out.extent_start is overwritten with allocated GMFN bases
*/
struct xen_memory_reservation out;
/*
* [OUT] Number of input extents that were successfully exchanged:
* 1. The first @nr_exchanged input extents were successfully
* deallocated.
* 2. The corresponding first entries in the output extent list correctly
* indicate the GMFNs that were successfully exchanged.
* 3. All other input and output extents are untouched.
* 4. If not all input exents are exchanged then the return code of this
* command will be non-zero.
* 5. THIS FIELD MUST BE INITIALISED TO ZERO BY THE CALLER!
*/
xen_ulong_t nr_exchanged;
};
The fields that are relevant for the bug are in.extent_start, in.nr_extents, out.extent_start, out.nr_extents and nr_exchanged.
nr_exchanged is documented as always being initialized to zero by the guest - this is because it is not only used to return a result value, but also for hypercall preemption. When memory_exchange() is preempted, it stores its progress in nr_exchanged, and the next execution of memory_exchange() uses the value of nr_exchanged to decide at which point in the input arrays in.extent_start and out.extent_start it should resume.
Originally, memory_exchange() did not check the userspace array pointers at all before accessing them with __copy_from_guest_offset() and __copy_to_guest_offset(), which do not perform any checks themselves - so by supplying hypervisor pointers, it was possible to cause Xen to read from and write to hypervisor memory - a pretty severe bug. This was discovered in 2012 (XSA-29, CVE-2012-5513) and fixed as follows (https://xenbits.xen.org/xsa/xsa29-4.1.patch):
diff --git a/xen/common/memory.c b/xen/common/memory.c
index 4e7c234..59379d3 100644
--- a/xen/common/memory.c
+++ b/xen/common/memory.c
@@ -289,6 +289,13 @@ static long memory_exchange(XEN_GUEST_HANDLE(xen_memory_exchange_t) arg)
goto fail_early;
}
+ if ( !guest_handle_okay(exch.in.extent_start, exch.in.nr_extents) ||
+ !guest_handle_okay(exch.out.extent_start, exch.out.nr_extents) )
+ {
+ rc = -EFAULT;
+ goto fail_early;
+ }
+
/* Only privileged guests can allocate multi-page contiguous extents. */
if ( !multipage_allocation_permitted(current->domain,
exch.in.extent_order) ||
The bug
As can be seen in the following code snippet, the 64-bit resumption offset nr_exchanged, which can be controlled by the guest because of Xen's hypercall resumption scheme, can be used by the guest to choose an offset from out.extent_start at which the hypervisor should write:
static long memory_exchange(XEN_GUEST_HANDLE_PARAM(xen_memory_exchange_t) arg)
{
[...]
/* Various sanity checks. */
[...]
if ( !guest_handle_okay(exch.in.extent_start, exch.in.nr_extents) ||
!guest_handle_okay(exch.out.extent_start, exch.out.nr_extents) )
{
rc = -EFAULT;
goto fail_early;
}
[...]
for ( i = (exch.nr_exchanged >> in_chunk_order);
i < (exch.in.nr_extents >> in_chunk_order);
i++ )
{
[...]
/* Assign each output page to the domain. */
for ( j = 0; (page = page_list_remove_head(&out_chunk_list)); ++j )
{
[...]
if ( !paging_mode_translate(d) )
{
[...]
if ( __copy_to_guest_offset(exch.out.extent_start,
(i << out_chunk_order) + j,
&mfn, 1) )
rc = -EFAULT;
}
}
[...]
}
[...]
}
However, the guest_handle_okay() check only checks whether it would be safe to access the guest array exch.out.extent_start starting at offset 0; guest_handle_subrange_okay() would have been correct. This means that an attacker can write an 8-byte value to an arbitrary address in hypervisor memory by choosing:
- exch.in.extent_order and exch.out.extent_order as 0 (exchanging page-sized blocks of physical memory for new page-sized blocks)
- exch.out.extent_start and exch.nr_exchanged so that exch.out.extent_start points to userspace memory while exch.out.extent_start+8*exch.nr_exchanged points to the target address in hypervisor memory, with exch.out.extent_start close to NULL; this can be calculated as exch.out.extent_start=target_addr%8, exch.nr_exchanged=target_addr/8.
- exch.in.nr_extents and exch.out.nr_extents as exch.nr_exchanged+1
- exch.in.extent_start as input_buffer-8*exch.nr_exchanged (where input_buffer is a legitimate guest kernel pointer to a physical page number that is currently owned by the guest). This is guaranteed to always point to the guest userspace range (and therefore pass the access_ok() check) because exch.out.extent_start roughly points to the start of the userspace address range and the hypervisor and guest kernel address ranges together are only as big as the userspace address range.
The value that is written to the attacker-controlled address is a physical page number (physical address divided by the page size).
Exploiting the bug: Gaining pagetable control
Especially on a busy system, controlling the page numbers that are written by the kernel might be difficult. Therefore, for reliable exploitation, it makes sense to treat the bug as a primitive that permits repeatedly writing 8-byte values at controlled addresses, with the most significant bits being zeroes (because of the limited amount of physical memory) and the least significant bits being more or less random. For my exploit, I decided to treat this primitive as one that writes an essentially random byte followed by seven bytes of garbage.
It turns out that for an x86-64 PV guest, such a primitive is sufficient for reliably exploiting the hypervisor for the following reasons:
- x86-64 PV guests know the real physical page numbers of all pages they can access
- x86-64 PV guests can map live pagetables (from all four paging levels) belonging to their domain as readonly; Xen only prevents mapping them as writable
- Xen maps all physical memory as writable at 0xffff830000000000 (in other words, the hypervisor can write to any physical page, independent of the protections using which it is mapped in other places, by writing to physical_address+0xffff830000000000).
The goal of the attack is to point an entry in a live level 3 pagetable (which I'll call "victim pagetable") to a page to which the guest has write access (which I'll call "fake pagetable"). This means that the attacker has to write an 8-byte value, containing the physical page number of the fake pagetable and some flags, into an entry in the victim pagetable, and ensure that the following 8-byte pagetable entry stays disabled (e.g. by setting the first byte of the following entry to zero). Essentially, the attacker has to write 9 controlled bytes followed by 7 bytes that don't matter.
Because the physical page numbers of all relevant pages and the address of the writable mapping of all physical memory are known to the guest, figuring out where to write and what value to write is easy, so the only remaining problem is how to use the primitive to actually write data.
Because the attacker wants to use the primitive to write to a readable page, the "write one random byte followed by 7 bytes of garbage" primitive can easily be converted to a "write one controlled byte followed by 7 bytes of garbage" primitive by repeatedly writing a random byte and reading it back until the value is right. Then, the "write one controlled byte followed by 7 bytes of garbage" primitive can be converted to a "write controlled data followed by 7 bytes of garbage" primitive by writing bytes to consecutive addresses - and that's exactly the primitive needed for the attack.
At this point, the attacker can control a live pagetable, which allows the attacker to map arbitrary physical memory into the guest's virtual address space. This means that the attacker can reliably read from and write to the memory, both code and data, of the hypervisor and all other VMs on the system.
Running shell commands in other VMs
At this point, the attacker has full control over the machine, equivalent to the privilege level of the hypervisor, and can easily steal secrets by searching through physical memory; and a realistic attacker probably wouldn't want to inject code into VMs, considering how much more detectable that makes an attack.
But running an arbitrary shell command in other VMs makes the severity more obvious (and it looks cooler), so for fun, I decided to continue my exploit so that it injects a shell command into all other 64-bit PV domains.
As a first step, I wanted to reliably gain code execution in hypervisor context. Given the ability to read and write physical memory, one relatively OS- (or hypervisor-)independent way to call an arbitrary address with kernel/hypervisor privileges is to locate the Interrupt Descriptor Table using the unprivileged SIDT instruction, write an IDT entry with DPL 3 and raise the interrupt. (Intel's upcoming Cannon Lake CPUs are apparently going to support User-Mode Instruction Prevention (UMIP), which will finally make SIDT a privileged instruction.) Xen supports SMEP and SMAP, so it isn't possible to just point the IDT entry at guest memory, but using the ability to write pagetable entries, it is possible to map a guest-owned page with hypervisor-context shellcode as non-user-accessible, which allows it to run despite SMEP.
Then, in hypervisor context, it is possible to hook the syscall entry point by reading and writing the IA32_LSTAR MSR. The syscall entry point is used both for syscalls from guest userspace and for hypercalls from guest kernels. By mapping an attacker-controlled page into guest-user-accessible memory, changing the register state and invoking sysret, it is possible to divert the execution of guest userspace code to arbitrary guest user shellcode, independent of the hypervisor or the guest operating system.
My exploit injects shellcode into all guest userspace processes that is invoked on every write() syscall. Whenever the shellcode runs, it checks whether it is running with root privileges and whether a lockfile doesn't exist in the guest's filesystem yet. If these conditions are fulfilled, it uses the clone() syscall to create a child process that runs an arbitrary shell command.
(Note: My exploit doesn't clean up after itself on purpose, so when the attacking domain is shut down later, the hooked entry point will quickly cause the hypervisor to crash.)
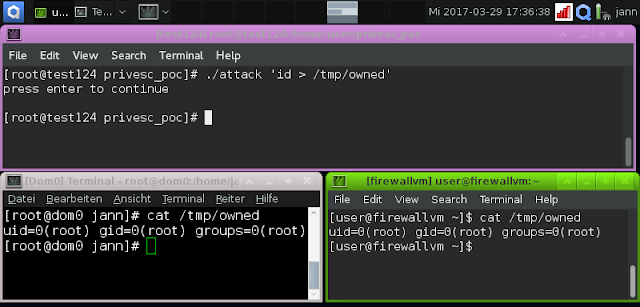
Here is a screenshot of a successful attack against Qubes OS 3.2, which uses Xen as its hypervisor. The exploit is executed in the unprivileged domain "test124"; the screenshot shows that it injects code into dom0 and the firewallvm:

For security researchers, I think that a lesson from this is that paravirtualization is not much harder to understand than normal kernels. If you've audited kernel code before, the hypercall entry path (lstar_enter and int80_direct_trap in xen/arch/x86/x86_64/entry.S) and the basic design of hypercall handlers (for x86 PV: listed in the pv_hypercall_table in xen/arch/x86/pv/hypercall.c) should look more or less like normal syscalls.
Conclusion
I believe that the root cause of this issue were the weak security guarantees made by access_ok(). The current version of access_ok() was committed in 2005, two years after the first public release of Xen and long before the first XSA was released. It seems like old code tends to contain relatively straightforward weaknesses more often than newer code because it was committed with less scrutiny regarding security issues, and such old code is then often left alone.
When security-relevant code is optimized based on assumptions, care must be taken to reliably prevent those assumptions from being violated. access_ok() actually used to check whether the whole range overlaps hypervisor memory, which would have prevented this bug from occurring. Unfortunately, in 2005, a commit with "x86_64 fixes/cleanups" was made that changed the behavior of access_ok() on x86_64 to the current one. As far as I can tell, the only reason this didn't immediately make the MEMOP_increase_reservation and MEMOP_decrease_reservation hypercalls vulnerable is that the nr_extents argument of do_dom_mem_op() was only 32 bits wide - a relatively brittle defense.
While there have been several Xen vulnerabilities that only affected PV guests because the issues were in code that is unnecessary when dealing with HVM guests, I believe that this isn't one of them. Accessing guest virtual memory is much more straightforward for PV guests than for HVM guests: For PV guests, raw_copy_from_guest() calls copy_from_user(), which basically just does a bounds check followed by a memcpy with pagefault fixup - the same thing normal operating system kernels do when accessing userspace memory. For HVM guests, raw_copy_from_guest() calls copy_from_user_hvm(), which has to do a page-wise copy (because the memory area might be physically non-contiguous and the hypervisor doesn't have a contiguous virtual mapping of it) with guest pagetable walks (to translate guest virtual addresses to guest physical addresses) and guest frame lookups for every page, including reference counting, mapping guest pages into hypervisor memory and various checks to e.g. prevent HVM guests from writing to readonly grant mappings. So for HVM, the complexity of handling guest memory accesses is actually higher than for PV.
For security researchers, I think that a lesson from this is that paravirtualization is not much harder to understand than normal kernels. If you've audited kernel code before, the hypercall entry path (lstar_enter and int80_direct_trap in xen/arch/x86/x86_64/entry.S) and the basic design of hypercall handlers (for x86 PV: listed in the pv_hypercall_table in xen/arch/x86/pv/hypercall.c) should look more or less like normal syscalls.
Rename the functions (or create new ones and issue warnings for using the old names). Something like guest_handle_okay_head and guest_handle_okay_range. Would have made it more likely to catch the bug during patch review.
ReplyDelete