Posted by James Forshaw currently impersonating NT AUTHORITY\SYSTEM.
Much as I enjoy the process of vulnerability research sometimes there’s a significant disparity between the difficulty of finding a vulnerability and exploiting it. The Project Zero blog contains numerous examples of complex exploits for seemingly trivial vulnerabilities. You might wonder why we’d go to this level of effort to prove exploitability, surely we don’t need to do so? Hopefully by the end of this blog post you’ll have a better understanding of why it’s often the case we spend a significant effort to demonstrate a security issue by developing a working proof of concept.
Our primary target for a PoC is the vendor, but there are other benefits for developing one. A customer of the vendor’s system can use the PoC to test whether they’re vulnerable to the issue and ensure any patch has been correctly applied. And the security industry can use it to develop mitigations and signatures for the vulnerability even if the vendor is not willing or able to patch. Without the PoC being made available only people who reverse engineer the patch are likely to know about it, and they might not have your best interests in mind.
I don’t want this blog post to get bogged down in too much technical detail about the bug (CVE-2015-0002 for reference). Instead I’m going to focus on the process of taking that relatively simple vulnerability, determining exploitability and developing a PoC. This PoC should be sufficient for a vendor to make a reasonable assessment of the presented vulnerability to minimize their triage efforts. I’ll also explain my rationale for taking various shortcuts in the PoC development and why it has to be so.
Reporting a Vulnerability
One of the biggest issues with vulnerability research on closed or proprietary systems is dealing with the actual reporting process to get a vulnerability fixed. This is especially the case in complex or non-obvious vulnerabilities. If the system is open source, I could develop a patch, submit it and it stands a chance of getting fixed. For a closed source system I will have to go through the process of reporting. To understand this better let’s think about what a typical large vendor might need to do when receiving external security vulnerability reports.

This is a really simplified view on vulnerability response handling but it’s sufficient to explain the principles. For a company which develops the majority of their software internally I would have little influence over the patching cycle, but I can make a difference in the triage cycle. The easier I can make the vendor’s life the shorter the triage cycle can be and the quicker we can get a patch released. Everyone wins, except hopefully the people who might be using this vulnerability already. Don’t forget just because I didn’t know about this vulnerability before doesn’t mean it isn’t already known about.
In an ideal vulnerability research world (i.e. one in which I have to do the least amount of non-research work) if I find a bug all I’d need to do is write up some quick notes about it, send it to a vendor, they’ll understand the system, they’ll immediately move heaven and earth to develop the patch, job done. Of course it doesn’t work that way, sometimes just getting a vendor to recognize there’s even a security issue is an important first step. There can be a significant barrier between moving from the triage cycle to the patch cycle, especially as they’re usually separate entities inside a company. To provide for the best chance possible I’ll do two things:
- Put together a report of sufficient detail so the vendor understands the vulnerability
- Develop a PoC which unequivocally demonstrates the security impact
Writing up a Report
Writing up a report for the vendor is pretty crucial to getting an issue fixed, although it isn’t sufficient in many cases. You can imagine if I wrote something like, “Bug in ahcache.sys, fixit, *lol*” that doesn’t really help the vendor much. At the very least I’d want to provide some context such as what systems the vulnerability affects (and doesn’t affect), what the impact of the vulnerability is (to the best of my knowledge) and what area of the system the issue resides.
Why wouldn’t just the report be sufficient? Think about how a large modern software product is developed. It’s likely developed between a team of people who might work on individual parts. Depending on the age of the vulnerable code the original developer might have moved on to other projects, left the company entirely or been hit by the number 42 bus. Even if it’s relatively recent code written by a single person who’s still around to talk to it doesn’t mean they remember how the code works. Anyone who’s developed software of any size will have come across code they wrote, a month, week or even a day ago and wondered how it works. There’s a real possibility that the security researcher who’s spent time going through the executable instruction by instruction might know it better than anyone in the world.
Also you can think about the report in a scientific sense, it’s your vulnerability hypothesis. Some vulnerabilities can be proven, for example a buffer overflow can typically be proven mathematically, placing 10 things into space for 5 doesn’t work. But in many cases there’s nothing better than empirical proof of exploitability. If done right it can be experimentally validated by both the reporter and the vendor, this is the value of a proof-of-concept. Correctly developed the vendor can observe the effects of the experiment, converting my hypothesis to a theory which no-one can disprove.
Proving Exploitability through Experimentation
So the hypothesis posits that the vulnerability has a real-world security impact, we’ll prove it objectively using our PoC. In order to do this we need to provide the vendor not just with the mechanism to prove that the vulnerability is real but also clear observations that can be made and why those observations constitute a security issue.
What observations need to be made depend on the type of vulnerability. For memory corruption vulnerabilities it might be sufficient to demonstrate an application crashing in response to certain input. This isn’t always the case, some memory corruptions don’t provide the attacker any useful control. Therefore demonstrating control over the current execution flow, such as controlling the EIP register is usually the ideal.
For logical vulnerabilities it might be more nuanced, such as you can write a file to a location you shouldn’t be able to or the calculator application ends up running with elevated privileges. There’s no one-size-fits-all approach, however at the very least you want to demonstrate some security impact which can be observed objectively.
The thing to understand is I’m not developing a PoC for the purposes of being a useful exploit (from an attacker perspective) but to prove it’s a security issue to a sufficient level of confidence that it will get fixed. Unfortunately it isn’t always easy to separate these two aspects and sometimes without demonstrating local privilege escalation or remote code execution it isn’t taken as seriously as it should be.
Developing a Proof of Concept
Now let’s go into some of the challenges I faced in developing a PoC for the ahcache vulnerability I identified. Let’s not forget there’s a trade off between the time spent developing a PoC and the chance of the vulnerability being fixed. If I don’t spend enough time to develop a working PoC the vendor could turn around and not fix the vulnerability, on the other hand the more time I spend the longer this vulnerability exists which is potentially as bad for users.
Vulnerability Technical Details
Having a bit of understanding of the vulnerability will help us frame the discussion later. You can view the issue here with the attached PoC that I sent to Microsoft. The vulnerability exists in the ahcache.sys driver which was introduced in Windows 8.1 but in essence this driver implements the Windows native system call NtApphelpCacheControl. This system call handles a local cache for application compatibility information which is used to correct application behaviour on newer versions of Windows. You can read more about application compatibility here.
Some operations of this system call are privileged so the driver does a check of the current calling application to ensure they have administrator privileges. This is done in the function AhcVerifyAdminContext which looks something like the following code:
BOOLEAN AhcVerifyAdminContext()
{
BOOLEAN CopyOnOpen;
BOOLEAN EffectiveOnly;
SECURITY_IMPERSONATION_LEVEL ImpersonationLevel;
PACCESS_TOKEN token = PsReferenceImpersonationToken(
BOOLEAN EffectiveOnly;
SECURITY_IMPERSONATION_LEVEL ImpersonationLevel;
PACCESS_TOKEN token = PsReferenceImpersonationToken(
NtCurrentThread(),
&CopyOnOpen,
&EffectiveOnly,
&ImpersonationLevel);
&CopyOnOpen,
&EffectiveOnly,
&ImpersonationLevel);
if (token == NULL) {
token = PsReferencePrimaryToken(NtCurrentProcess());
}
PSID user = GetTokenUser(token);
if(RtlEqualSid(user, LocalSystemSid) || SeTokenIsAdmin(token)) {
return TRUE;
}
return FALSE;
}
This code queries to see if the current thread is impersonating another user. Windows allows a thread to pretend to be someone else on the system so that security operations can be correctly evaluated. If the thread is impersonating a pointer to an access token is returned. If NULL is returned from PsReferenceImpersonationToken the code queries for the current process’ access token. Finally the code checks whether either the access token’s user is the local system user or the token is a member of the Administrators group. If the function returns TRUE then the privileged operation is allowed to go ahead.
This all seems fine, so what’s the issue? While full impersonation is a privileged operation limited to users which have the impersonate privilege in their token, a normal user without the privilege can impersonate other users for non-security related functions. The kernel differentiates between privileged and unprivileged impersonation by assigning a security level to the token when impersonation is enabled. To understand the vulnerability there’s only two levels of interest, SecurityImpersonation which means the impersonation is privileged and SecurityIdentification which is unprivileged.
If the token is assigned SecurityIdentification only operations such as querying for token information, such as the token’s user is allowed. If you try and open a secured resource such as a file the kernel will deny access. This is the underlying vulnerability, if you look at the code the PsReferenceImpersonationToken returns a copy of the security level assigned to the token, however the code fails to verify it’s at SecurityImpersonation level. This means a normal user, who was able to get hold of a Local System access token could impersonate at SecurityIdentification and still pass the check as querying for the user is permitted.
Proving Trivial Exploitation
Exploiting the bug requires capturing a Local System access token, impersonating it and then calling the system call with appropriate parameters. This must be achievable from normal user privilege otherwise it isn’t a security vulnerability. The system call is undocumented so if we wanted to take a shortcut could we just demonstrate that we can capture the token and leave it at that?
Well not really, what this PoC would demonstrate is that something which is documented as possible is indeed possible. Namely that it’s possible from a normal user to capture the token and impersonate it, as the impersonation system is designed this would not cause a security issue. I knew already that COM supports impersonation, that there’s a number of complex system privileged services (for example BITS) we can communicate with as a normal user that we could convince to communicate back to our application in order to perform the impersonation. This wouldn’t demonstrate that we can even reach the vulnerable AhcVerifyAdminContext method in the kernel let alone successfully bypass the check.
So starts the long process of reverse engineering to work out how the system call works and what parameters you need to pass to get it to do something useful. There’s some existing work from other researchers (such as this) but certainly nothing concrete to take forward. The system call supports a number of different operations, it turned out that not all the operations needed complex parameters. For example the the AppHelpNotifyStart and AppHelpNotifyStop operations could be easily called, and they relied on the AhcVerifyAdminContext function. I could now produce a PoC which we can verify bypasses the check by observing the system call’s return code.
BOOL IsSecurityVulnerability() {
ImpersonateLocalSystem();
NTSTATUS status = NtApphelpCacheControl(AppHelpNotifyStop, NULL);
return status != STATUS_ACCESS_DENIED;
}
Is this sufficient to prove exploitability? History has taught me no, for example this issue has almost the exact same sort of operation, namely you can bypass an administrator check through impersonation. In this case I couldn’t produce sufficient evidence that it was exploitable for anything other than information disclosure. So in turn it was not fixed, even though it was effectively a security issue. To give ourselves the best chance of proving exploitability we need to spend more time on this PoC.
Improving the Proof-of-Concept
In order to improve upon the first PoC I would need to get a better understanding of what the system call is doing. The application compatibility cache is used to store the lookup data from the application compatibility database. This database contains rules which tell the application compatibility system what executables to apply “shims” to in order implement custom behaviours, such as lying about the operating system’s version number to circumvent an incorrect check. The lookup is made every time a process is created, if a suitable matching entry is found it’ll be applied to the new process. The new process will then lookup the shim data it needs to apply from the database.

As this occurs every time a new process is created there’s a significant performance impact in going to database file every time. The cache is there to reduce this impact, the database lookup can be added to the cache. If that executable is created later the cached lookup can quickly eliminate the expensive database lookup and either apply a set of shims or not.

Therefore we should be able to cache an existing lookup and apply it to an arbitrary executable. So I spent some time working out the format of the parameters to the system call in order to add my own cached lookup. The resulting structure for Windows 8.1 32 bit looked like the following:
struct ApphelpCacheControlData {
BYTE unk0[0x98];
DWORD query_flags;
DWORD cache_flags;
HANDLE file_handle;
HANDLE process_handle;
UNICODE_STRING file_name;
UNICODE_STRING package_name;
DWORD buf_len;
LPVOID buffer;
BYTE unkC0[0x2C];
UNICODE_STRING module_name;
BYTE unkF4[0x14];
};
You can see there’s an awful lot of unknown parts in the structure. This causes a problem if you were to apply this to Windows 7 (which has a slightly different structure) or 64 bit (which has a different sized structure) but for our purposes it doesn’t matter. We’re not supposed to be writing code to exploit all versions of Windows, all we need to do is prove the security issue to the vendor. As long as you inform the vendor of the PoC limitations (and they pay attention to them) we can do this. The vendor’s still better placed to determine if this PoC proves exploitability across versions of the OS, it’s their product after all.
So I could now add an arbitrary cached entry but what can we actually add? I could only add an entry which would have been the result of an existing lookup. You could modify the database to do something like patch running code (the application compatibility system is also used for hotfixes) but that would require administrator privileges. So I needed an existing shim to repurpose.
I built a copy of the SDB explorer tool (available from here) so that I could dump the existing database looking for any useful existing shim. I found that for 32 bit there’s a shim which will cause a process to start the executable regsvr32.exe passing the original command line. This tool will load a DLL passed on the command line and execute specific exported methods, if we could control the command line of a privileged process we could redirect it and elevate privileges.
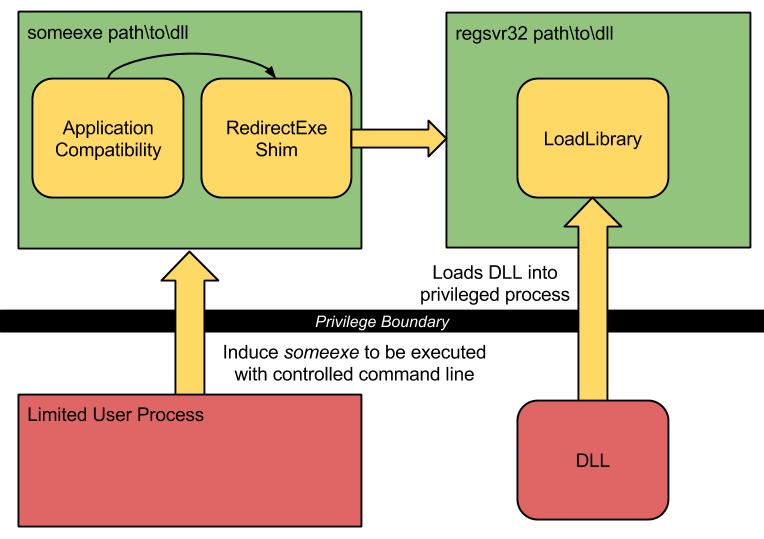
This again limits the PoC to only 32 bit processes but that’s fine. The final step, and what caused a lot of confusion was what process to choose to redirect. I could have spent a lot of time investigating other ways of achieving the requirement of starting a process where I control the command line. I already knew one way of doing it, UAC auto elevation. Auto elevation is a feature added to Windows 7 to reduce the number of UAC dialogs a typical user sees. The OS defines a fixed list of allowed auto elevating applications, when UAC is at it’s default setting then requests to elevate these applications do not show a dialog when the user’s an administrator. I can abuse this by applying a cache entry for an existing auto elevating application (in this case I chose ComputerDefaults.exe) and requesting the application runs elevated. This elevated application redirects to regsvr32 passing our fully controlled command line, regsvr32 loads my DLL and we’ve now got code executing with elevated privileges.
The PoC didn’t give someone anything they couldn’t already do through various other mechanisms (such as this metasploit module) but it was never meant to. It sufficiently demonstrated the issue by providing an observable result (arbitrary code running as an administrator), from this Microsoft were able to reproduce it and fix it.
Final Bit of Fun
As there was some confusion on whether this was only a UAC bypass I decided to spend a little time to develop a new PoC which gets local system privileges without any reliance on UAC. Sometimes I enjoy writing exploits, if only to prove that it can be done. To convert the original PoC to one which gets local system privileges I need a different application to redirect. I decided the most likely target was a registered scheduled task as you can sometimes pass arbitrary arguments to the task handler process. So we’ve got three criteria for the ideal task, a normal user must be able to start it, it must result in a process starting as local system and that process must have an arbitrary command line specified by the user. After a bit of searching I found the ideal candidate, the Windows Store Maintenance Task. As we can see if runs as the local system user.

We can determine that a normal user can start it by looking at the task file’s DACL using a tool such as icacls. Notice the entry in the following screenshot for NT AUTHORITY\Authenticated Users with Read and Execute (RX) permissions.
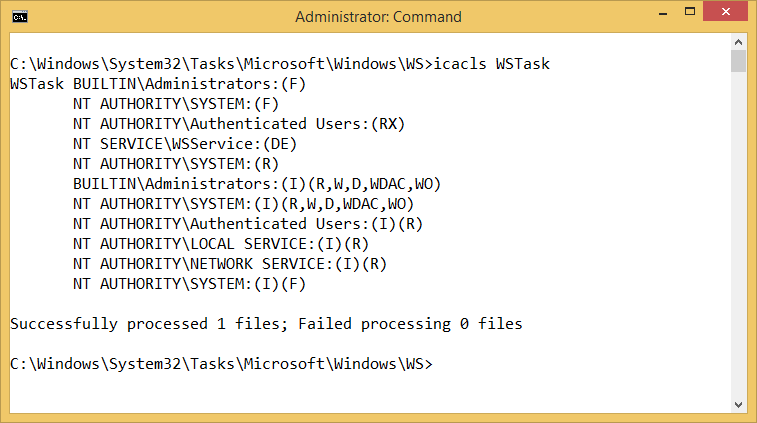
Finally we can check whether a normal user can pass any arguments to the task by checking the XML task file. In the case of WSTask it uses a custom COM handler, but allows the user to specify two command line arguments. This results in the executable c:\windows\system32\taskhost.exe executing with an arbitrary command line as the local system user.

It was just a case of modifying the PoC to add a cache entry for taskhost.exe and start the task with the path to our DLL. This still has a limitation, specifically it only works on 32 bit Windows 8.1 (there’s no 32 bit taskhost.exe on 64 bit platforms to redirect). Still I’m sure it can be made to work on 64 bit with a bit more effort. As the vulnerability is now fixed I’ve made available the new PoC, it’s attached to the original issue here.
Conclusions
I hope I’ve demonstrated some of the effort a vulnerability researcher would go to in order to ensure a vulnerability will be fixed. It’s ultimately a trade off between the time spent developing the PoC and the chances of the vulnerability being fixed, especially when the vulnerability is complex or non-obvious.
In this case I felt I made the right trade-off. Even though the PoC I sent to Microsoft looked, on the surface to only be a UAC bypass combined with the report they were able to determine the true severity and develop the patch. Of course if they’d pushed back and claimed it was not exploitable then I would have developed a more robust PoC. As a further demonstration of the severity I did produce a working exploit which gained local system privileges from a normal user account.
Disclosing the PoC exploit is of value to aid in a user’s or security company’s mitigation of a public vulnerability. Without a PoC it’s quite difficult to verify that a security issue has been patched or mitigated. It also helps to inform researchers and developers what types of issues to look out for when developing certain security sensitive applications. Bug hunting is not the sole approach for Project Zero to help secure software, education is just as important.
Project Zero’s mission involves tackling software vulnerabilities, and the development of PoCs can be an important part of our duty to help software vendors or open source projects take informed action to fix vulnerabilities.
awesome work James! out of curiousity, how do i join your team? :) :)
ReplyDelete