Posted by Mark Brand, Invalidator of Unic�o�d�e
I’ve been investigating different fuzzing approaches on some Android devices recently, and this turned up the following rather interesting bug (CVE 2016-3861 fixed in the most recent Android Security Bulletin), deep in the bowels of the usermode Android system. It’s an extremely serious bug, since the vulnerable code path is accessible from many different attack vectors, and it can be leveraged both for remote code execution and for local privilege elevation into the highly privileged system_server selinux domain. I’m a big fan of single bug chains [1] [2].
The bug is quite straightforward, and since it’s quite readily fuzzable, it’s interesting that it’s been undiscovered for so long. The vulnerable code is in libutils, and is in the conversion between UTF16 and UTF8. This code is used in many places, including the android::String8(const android::String16&) constructor.
The Bug
There are two functions in libutils/Unicode.cpp that need to match up; the first, utf16_to_utf8_length is used to compute the size of buffer needed to hold the UTF8 string that will be the result of converting the source UTF16 string, and utf16_to_utf8 performs the conversion. These functions are intended to be used together, to first allocate a buffer of the required size and then convert, and so it is obviously important that they agree on how many bytes of output are needed…
So, there is obviously some difference in behaviour between the functions; and we can fairly easily construct some input that will produce different behaviour in each. If you can’t see one easily, try walking through the logic in each function with the input string:
‘\x01\xd8\x02\xd8\x03\xdc\x00\x00’
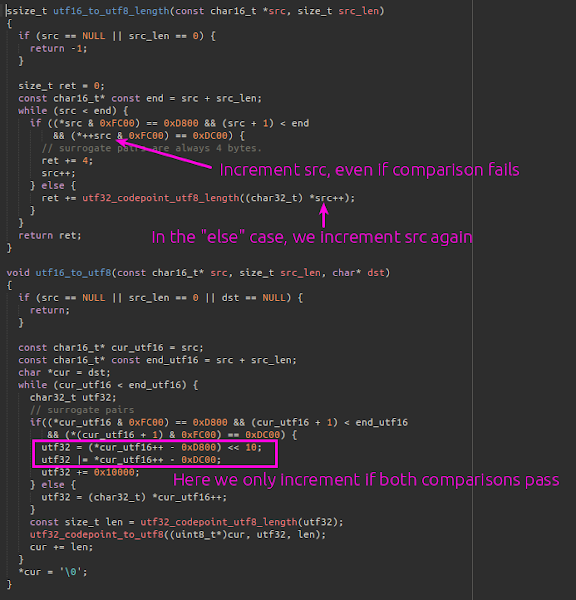
This will be seen by utf16_to_utf8_length as a string consisting of two invalid surrogate pairs, requiring 0 bytes of output to encode.
(0xd801, 0xd802), (0xdc03), (0x0000)
It will however be seen by utf16_to_utf8 as a string starting with an invalid surrogate pair, followed by a valid surrogate pair; which encodes to 4 bytes of output.
(0xd801, 0xd802), (0xd802, 0xdc03), (0x0000)
This gives quite a nice exploitation primitive; by creating a string containing valid UTF16, we can control the size of the allocation; and we control the size of the overflow, with the limitation that it must be a multiple of 4 bytes larger than the allocation. The only significant limitation is that the data that we overflow with needs to be valid UTF8, which will prove slightly annoying later on.
Attack Vectors
We need to identify a nice attack vector we can use to exploit this issue. Now, as I said earlier, this bug was found by fuzzing - can’t we just use the fuzz case? Well, it was found by fuzzing some OEM-specific code (the vendor isn’t relevant). We can find some core Android attack surface, and write an exploit that targets all Android devices instead.
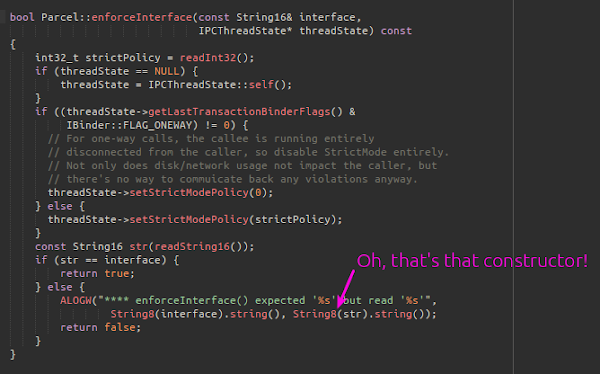
The first nice place I found is the following piece of code (in Parcel.cpp), which is interesting because the generated code for every* system service on an Android device calls this function on every parcel it receives. So, this should give us a privilege escalation from the untrusted_app context into any binder service we fancy; there are plenty of choices, but since there are so many inside system_server, why go anywhere else?
* Except the service_manager implements this logic itself, and probably some OEMS are rolling their own, but to all intents and purposes, this statement is true.
Anyway, I wanted a remote exploit, and it seemed likely that this code was being called in other places that were accessible remotely; maybe WiFi or Bluetooth, or DNS? Anyway, I looked around a bit, but the most obvious places were usually using the (completely distinct) libcutils implementations, and it was all a bit frustrating. Then I remembered, of course, mediaserver!
Sure enough, in the processing of ID3 tags, we sometimes need to handle unicode conversions.
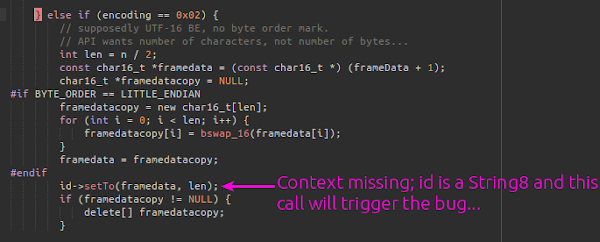
This is kind of convenient, since I’ve already done a lot of legwork understanding how to exploit libstagefright bugs. Producing a minimal crash PoC was straightforward, although slightly annoying since libstagefright doesn’t appear to parse the same ID3v2 format I found documentation for… The file is attached to the bug report, but it looks like this:
00000000: 0000 0014 6674 7970 6973 6f6d 0000 0001 ....ftypisom....
00000010: 6973 6f6d 0000 182f 7472 616b 0000 1827 isom.../trak...'
00000020: 4944 3332 4141 4141 4141 4944 3302 0200 ID32AAAAAAID3...
00000030: 0000 300f 5441 4c00 1809 0165 6e67 00fe ..0.TAL....eng..
00000040: ff41 d841 d841 dc41 d841 d841 dc41 d841 .A.A.A.A.A.A.A.A
...
00001830: d841 d841 dc41 d841 d841 dc41 d841 d841 .A.A.A.A.A.A.A.A
00001840: dc00 00 ...
A very simple file; just enough to get an ID3 tag read and processed that will trigger a large overflow out of a very small allocation. I’ve highlighted the first instance of the bad UTF16 sequence that will trigger the overflow; this sequence is just repeated many many times.
Mitigating Mitigations
My previous stagefright exploit was very crude; I was lazy and the only reason that I was writing the exploit at all was that I couldn’t bear to have another person ask me if the bug was at all exploitable on the latest Android versions. I was happy to stop working the minute I had something that worked and was plausible; but it wasn’t up to the usual standards I hold myself to…
So, anyway, this time, with a better bug and with a few of the shortcuts I took previously mitigated in the latest Android versions, it’s time to return to stagefright and do things properly this time. There’s been a fair amount of additional work in the public building on my PoC exploit; one reliable exploit that I’ve seen privately, and the exploit by NorthBit detailed here.
I’m not going to go into any real detail on the heap-grooming used here in this blog post; it’s already going to be a long post… Hopefully the exploit code and a debugger can teach you everything you need to know; I think the previous post and papers on stagefright exploitation probably cover everything but the precise specifics in this case, so I’ll just outline the steps that the exploit takes instead.
First things first, we need to solve the ASLR problem. The technique I originally considered to do this was implemented already by NorthBit, using the metadata returned to the browser to construct an information leak; this seems to be the simplest way. Another possibility would be to corrupt the objects used for communication with the remote HTTP server; the mediaserver process makes HTTP requests to retrieve the media file, and we could perhaps modify the headers to leak information; but I did not follow this route.
I looked at using the metadata corruption technique they implemented, but it seemed somewhat impractical to me. Even if we can predict “fairly reliably” a safe address to read from, there is another issue - Android have enabled the ubsan integer-overflow checking in their libstagefright builds; and the duration field has several arithmetic operations performed on it; and if any of those operations overflow, we don’t just lose bits of information, we abort!
So, we can’t practically use the duration. There are two more fields that can be retrieved from Chrome; the width and height of the video. These fields fit our needs perfectly; they’re pointer-sized, and they’re inline in the heap allocation for the metadata. Let’s see how we can use them to get all the information we need.
Step 1 - Heap pointer leak
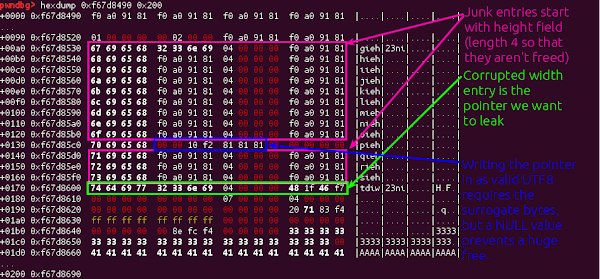
Our first step in bypassing ASLR is a partial bypass; we’d like to get data we control at an address that we know. We can do this using the video height to leak the address of some of the data parsed from our media file. For this, we need two things to line up nicely; the allocation that we will overflow out of needs to land directly in front of the SharedBuffer object that is providing the backing data store for the KeyedVector that stores the entries in the MetaData for one of our tracks.
The key realisation here is that the ‘hvcC’ chunks that I used in the heap groom for the previous exploit store a pointer to data we control inside the MetaData object; so by corrupting the backing vector we can instead make this pointer into the height of our video, letting us read it back from inside Chrome.
So, let’s attach a debugger to mediaserver and see what happens during the first part of the exploit.
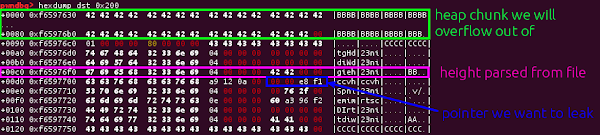
So to leak the address of the allocation caused by the ‘hvcC’ chunk, we just need to use the overflow to move the height entry down by a row, so that the height is instead the pointer!
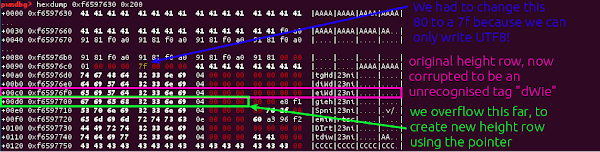
This value will then be handed back to Chrome as the height of the video, and we can read it back from javascript. This is a powerful primitive; and we’ll use this multiple times in the final exploit. First though, we just need to load this file repeatedly until we get an address that we can safely encode using UTF8; we’ll need a valid address that we can write using the overflow for the next step.
Step 2 - Module pointer leak
So, we have an address on the heap, next we need to leak the address of some executable code. This is going to be much more fiddly than the previous step; and we’ll actually have to trigger the same vulnerability twice in the same MP4 to achieve our goal.
If we look a bit more carefully at the object we are overflowing, another possibility opens up:
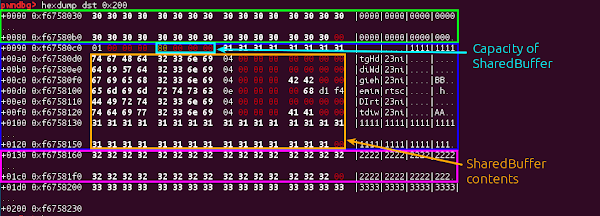
Instead of overwriting the contents of the SharedBuffer, we can corrupt the metadata and change the capacity of the SharedBuffer, so that it extends to include the next allocation as well. When more track information is parsed and stored in the MetaData object, the KeyedVector backing the MetaData will expect that it needs to resize the backing storage; and will request the SharedBuffer to allocate more data; the SharedBuffer will think it has plenty of space and just carry on.
So, as we know, we can only practically use this to leak things which are aligned in the last column of our hexdump; and this is not normally where we’d expect to find a vtable pointer; so we have to investigate the layout of all the objects we can create in the hope that we can find one that will place a useful pointer at an offset we can leak. As it happens, there is one such object; the SampleTable.
Allocating a SampleTable after the corrupted SharedBuffer will give us the following:
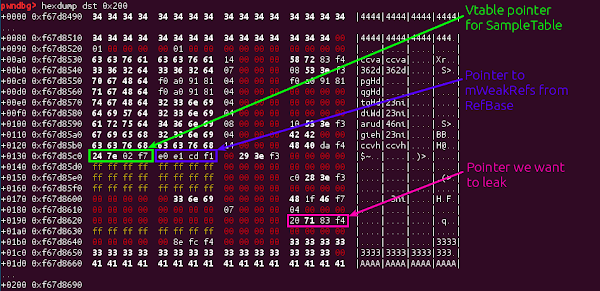
As you can see from the labels, there are a few things of note; the SampleTable vtable pointer is of no consequence to us - we can safely dispose of the SampleTable without calling any methods on it, just as long as we never decrement it’s refcount to 0; but the mWeakRefs pointer inherited from RefBase is a serious problem for us; this needs to be a pointer to somewhere that can be safely decremented and not result in a 0 refcount. Here’s where we will reuse the valid UTF8 pointer we leaked above.
Finally, we can see the target pointer; a vtable pointer in libmedia.so. It’s quite a long way down the allocation; and the number of entries in the KeyedVector is stored out-of-line; so we need to perform the following steps:
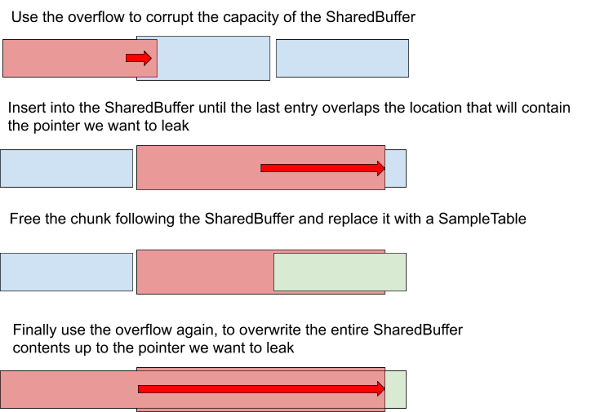
Here’s what everything looks like after the second overflow is completed;
There are a few bits of cleanup we need to do at the end of this file; adding a second sample table to the track prevents the other from being referenced, and then we need to add a couple of entries back to the MetaData to ensure the file finishes parsing correctly and the pointer we want will get returned to Chrome!
Step 3, 4, 5, 6 - An exercise for the reader
Well, we have two powerful primitives; the ability to leak the address of a block of data whose contents we control, and we know the base address of a relatively large and generously gadget-full module, libmedia.so. It’s no major stress from here to getting ROP execution in the mediaserver process using the same technique as my previous exploit; and from there to shellcode on Android M is simply a case of calling mprotect; which is even imported by libmedia.so. The provided exploit performs this on several recent Android versions for the Nexus 5x; and is both reliable and fast in my testing. It would also be possible to make the exploit faster by directly generating the exploit files in javascript, reducing the unnecessary network round-trips retrieving identical mp4 files. The exploit code is attached to the bug tracker here.
A slightly useful quirk that will make your ROPing life easier is the reference to mprotect in BnOMX::onTransact - it seems to be there for security reasons.
Final thoughts
I started working on this exploit on a build of the upcoming Android N release, and anyone sitting near my desk will testify to the increased aggravation this caused me. A lot of general hardening work has gone into N, and the results are impressive. That’s not to say that exploiting this bug was impossible on N - but a full chain would be significantly more complex. The initial steps to get control of the program are identical; the only significant change is that instead of mediaserver, the target process is a new one - mediaextractor, which runs in a more restrictive sandbox and no longer has the ‘execmem’ privilege, ruling out the mprotect route to shellcode, and meaning that a privilege elevation direct from ROP would be required.
A day or two later I had a fairly complicated self-modifying ROP chain to make the necessary C++ virtual calls to interact with other services from the new, heavily sandboxed, mediaextractor and I was ready to start working on the privilege elevation into system_server. However, every time I tested, attempts to lookup the system_server services failed - and looking in the logs I realised that I’d misunderstood the selinux policy. While the mediaextractor was allowed to make binder calls; it wasn’t permitted to lookup any other binder services! Privilege elevation on N would instead require exploiting an additional, distinct vulnerability.
As a sidenote - my original stagefright exploit used the fact that Chrome on Android provides the build-id in the useragent; an unnecessary weakness that makes fingerprinting versions from the browser completely trivial. It’s still a “feature” of the Android WebView and Chrome browser - hopefully this will be changed soon.
And like last time, new mitigations that could be set in place to make the Android exploitation process harder also came out of this research; and hopefully they’ll be making it into an Android release soon.








